 22 299 53 69
22 299 53 69
 biuro@jsystems.pl
biuro@jsystems.pl



Praktyczne wprowadzenie do Elastic Stack (Elasticsearch, Kibana, Logstash, Beats)
 4.85/5
4.85/5
Najbliższe terminy tego szkolenia
 18.06
18.06 Szkolenie online
Szkolenie online Ostatnie miejsca!
Ostatnie miejsca!
Standardy JSystems
- Wszyscy nasi trenerzy muszą być praktykami i osiągać średnią z ankiet minimum 4.75 na 5. Nie ma wśród nas trenerów-teoretyków. Każdy trener JSystems ma bogate doświadczenie komercyjne w zakresie tematów z których prowadzi szkolenia.
- Wszystkie szkolenia mają format warszatowy. Każde zagadnienie teoretyczne jest poparte rzędem warsztatów w ściśle określonym formacie.
- Terminy gwarantowane na 100%. Jeśli jakiś termin jest oznaczony jako gwarantowany, oznacza to że odbędzie się nawet jeśli część grupy wycofa się z udziału. Ryzyko ponosimy my jako organizator.
- Do każdego szkolenia które wymaga jakiegokolwiek oprogramowania dostarczamy skonfigurowane, gotowe hosty w chmurze. Dzięki temu uczestnik nie musi nic instalować na swoim komputerze (i bić się z blokadami korporacyjnymi). Połączenie następuje przez zdalny pulpit lub SSH - w zależności od szkolenia.
Program szkolenia
- ELK Stack – wprowadzenie
- Omówienie poszczególnych elementów (Elasticsearch, Kibana, Logstash, Beats)
- Rodzaje licencji oraz dostępne funkcjonalności
- Zalety i ograniczenia
- Podstawy Elasticsearch
- Tworzenie indeksów(na co zwracać uwagę)
- Mapowanie
- Typy i formaty danych
- Statyczne czy dynamiczne
- Dobre praktyki
- Index Templates (dlaczego warto stosować)
- Aliasy
- Indeks Patterny
- ILM (sposób na zarządzanie indeksami)
- Operacje na indeksach
- Kibana
- Wybrane funkcjonalności
- Wykorzystanie Discover
- Wizualizacje i ich zastosowanie
- Mapy
- Dashboardy
- Export do CSV
- Logstash
- Budowa oraz zasada działania
- Sposoby konfiguracji źródeł
- Plugin INPUT (jdbc, file , csv, beats)
- Plugin FILTER (csv, grok, mutate, date, kv)
- Plugin OUTPUT (stdout, file, elasticsearch)
- Beats
- Rodzaje i możliwości
- Konfiguracja Filebeata
- Praca z plikami
Opis szkolenia
Szkolenie odbywa się na żywo z udziałem trenera. Nie jest to forma kursu video!
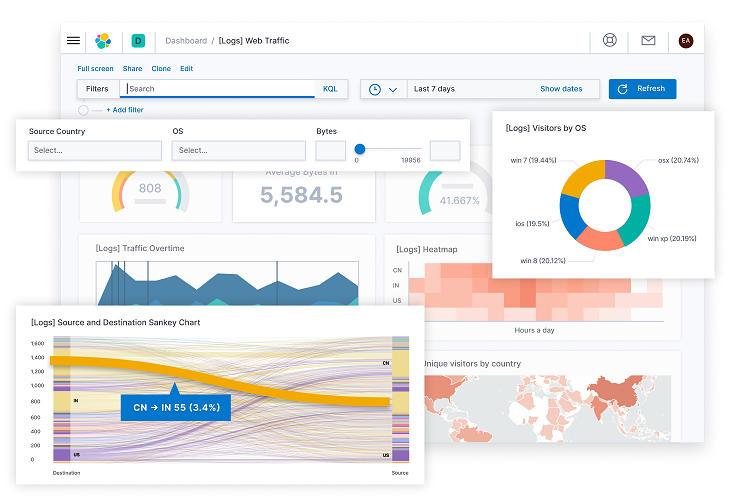
W skrócie
Celem szkolenia jest zapoznanie się z architekturą Elastic Stack oraz możliwościami w zakresie ładowania, przetwarzania i różnorodnej wizualizacji danych. Na początku omówimy poszczególne moduły: Elasticsearch, Kibana, Logstash, Beats. Następnie przejdziemy do praktycznych przykładów pracy z danymi. Po tym szkoleniu uczestnik dowie się, jakie są zalety korzystania z silnika Elasticsearch. Nauczy się tworzyć indeksy i efektywnie zarządzać nimi. Pozna sposoby ładowania danych pochodzących z różnych źródeł.
Dla kogo?
Szkolenie przeznaczone jest dla osób początkujących, które chcą się nauczyć środowiska Elastic Stack i zacząć pracę w tym systemie.
Charakter szkolenia
Szkolenie ma charakter warsztatowy. Każde omówione zagadnienie podsumowane będzie kilkoma ćwiczeniami, które pozwolą wykorzystać zdobytą wiedzę.
Przebieg szkolenia
Zajęcia rozpoczynamy od omówienia architektury ELK Stacka i zbudowaniu środowiska testowego. Następnie zapoznamy się bliżej z możliwościami przechowywania i wyszukiwania danych w bazie Elasticsearch oraz ich prezentacji w Kibanie. Następnie przejdziemy do omówienia modułu Logstash. Skupimy się na pracy z danymi pochodzącymi z różnych źródeł. Ostatnia część będzie poświęcona modułom Beats i ich praktycznemu zastosowaniu.
Stanowisko robocze

Do tego szkolenia każdy uczestnik otrzymuje dostęp do indywidualnej wirtualnej maszyny w chmurze. Ma ona zainstalowane i skonfigurowane wszystko co potrzebne do realizacji szkolenia. Maszyna będzie dostępna przez cały okres szkolenia.
 Terminy gwarantowane
Terminy gwarantowane
Gdy na jakiś termin zgłosi się minimalna liczba osób, termin oznaczamy jako gwarantowany.
Jeśli jakiś termin oznaczony jest jako gwarantowany to oznacza to, że na 100% się odbędzie we wskazanym czasie i miejscu.
Nawet gdyby część takiej grupy zrezygnowała lub przeniosła się na inny termin, raz ustalony termin gwarantowany takim pozostaje.
Ewentualne ryzyko ponosimy my jako organizator.
Przejdź do terminów tego szkolenia
 Szkolenia online
Szkolenia online odbywają się na żywo z udziałem trenera. Uczestniczy łączą się na szkolenie za pomocą platfomy ZOOM.
Informacje o wymaganym niezbędnym oprogramowaniu oraz informacje organizacyjne uczestnicy otrzymują na 7 dni przed datą rozpoczęcia szkolenia.
Szkolenia online
Szkolenia online odbywają się na żywo z udziałem trenera. Uczestniczy łączą się na szkolenie za pomocą platfomy ZOOM.
Informacje o wymaganym niezbędnym oprogramowaniu oraz informacje organizacyjne uczestnicy otrzymują na 7 dni przed datą rozpoczęcia szkolenia.
 Inne szkolenia tej kategorii
Inne szkolenia tej kategorii
Sprawdź, co mówią o nas ci, którzy nam zaufali
Trenerzy kategorii Elastic Stack (Elasticsearch)
 Elżbieta Jakubowska
Elżbieta Jakubowska
Elżbieta Jakubowska
Elżbieta Jakubowska


